The Replay Efficiency Gap
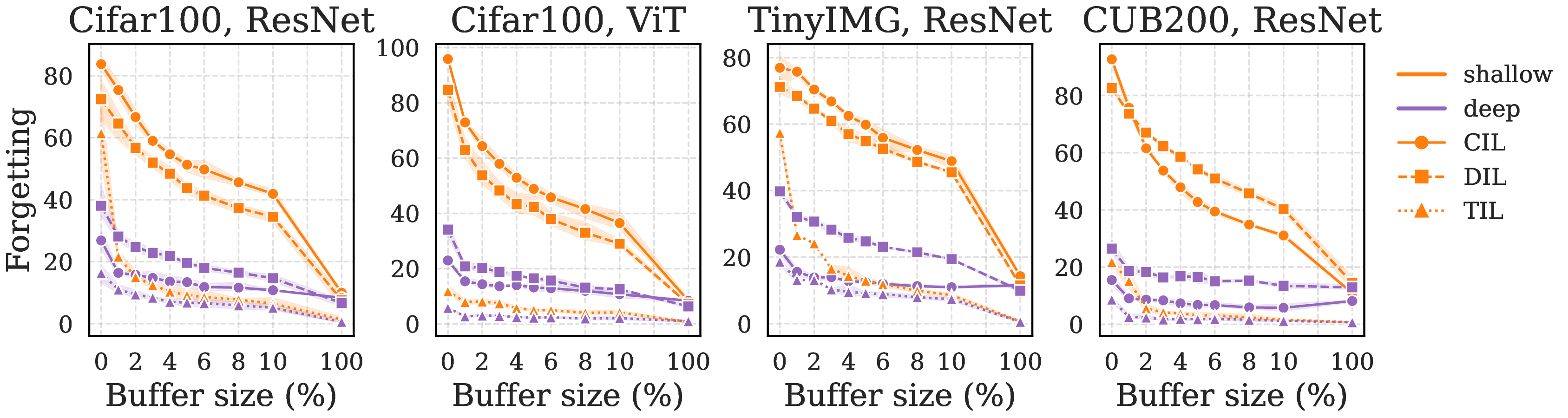
Forgetting decays at different rates in feature space vs. classifier head across buffer sizes
Connection to Out-of-Distribution Detection
Our Hypothesis
Forgotten samples behave as OOD data
- OOD features orthogonal to active subspace \(S\)
- Without replay: past tasks drift to \(S^\perp\), decay exponentially
Related work:
Ammar et al. (2024): NC5 property
Haas et al. (2023): L2 regularization & OOD
Kang et al. (2024): OOD collapse to origin
Past-task features project to zero in \(S\)
Consequences for Old Data
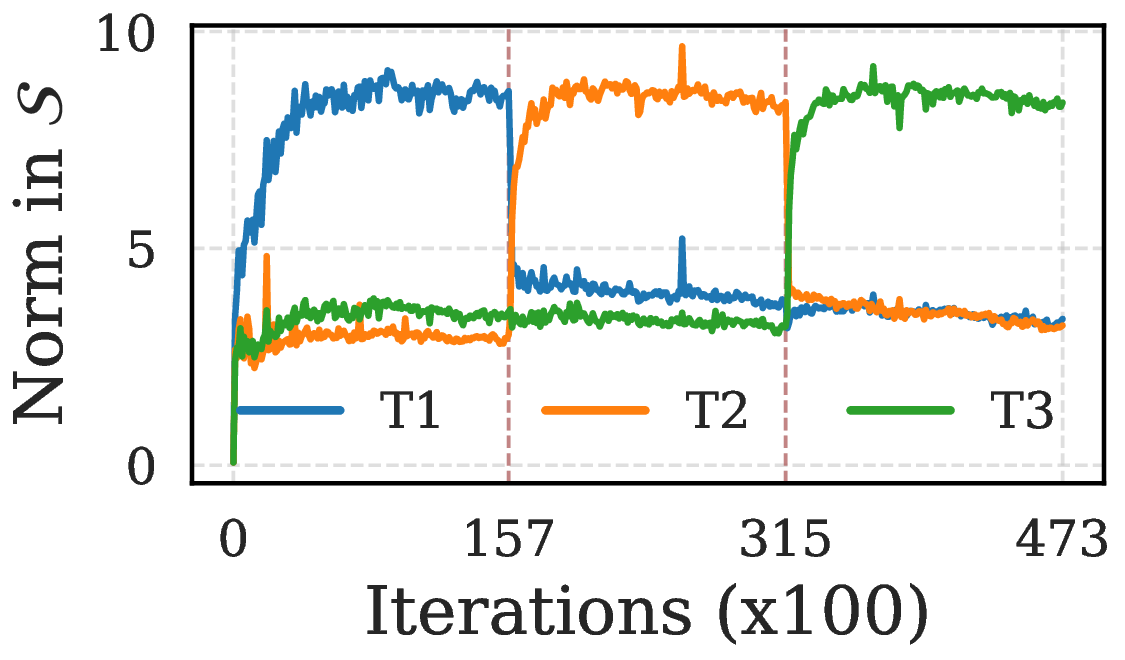
NC emerges consistently across tasks with replay
Without Replay
Old task representations drift into \(S^\perp\)
Exponential decay with weight decay
With Replay
Representations anchored in \(S\)
Buffer provides foothold in active subspace
Why Shallow Forgetting Persists
If features are separable, why do classifiers fail?
- Strong Collapse: Small buffers induce rank-deficient covariances
- Under-determined Classifier: Multiple "buffer-optimal" boundaries fit stored samples perfectly
- Statistical Gap: Buffer estimates deviate from population statistics
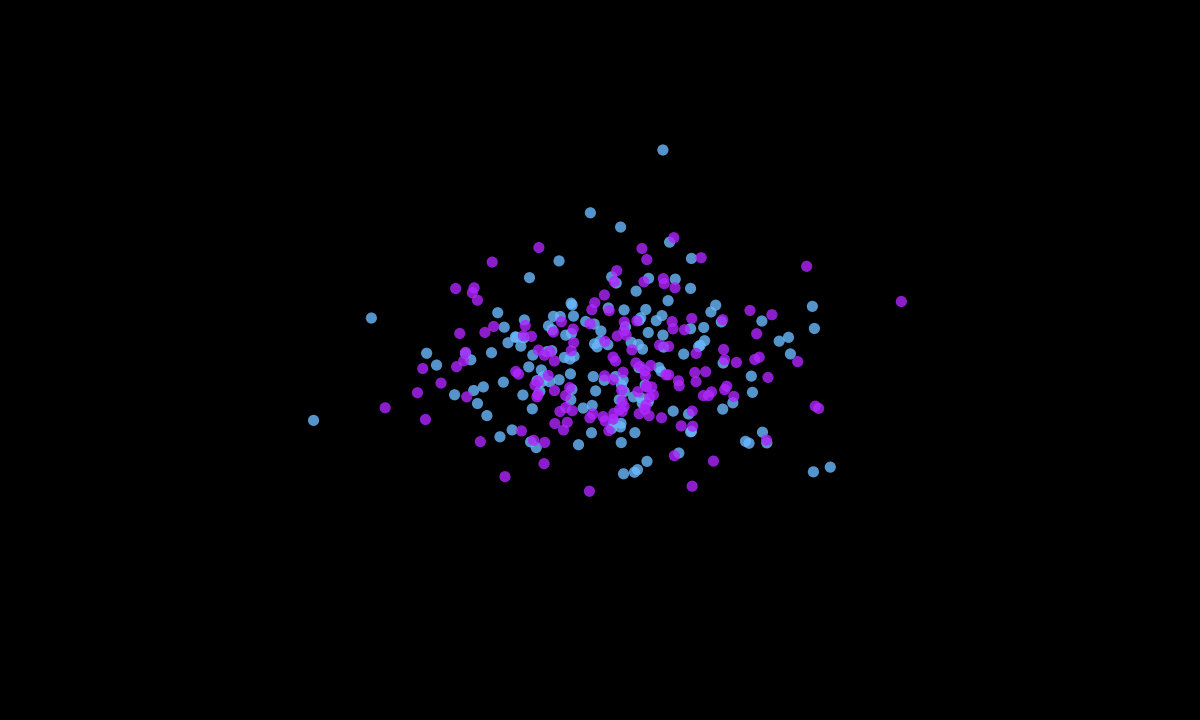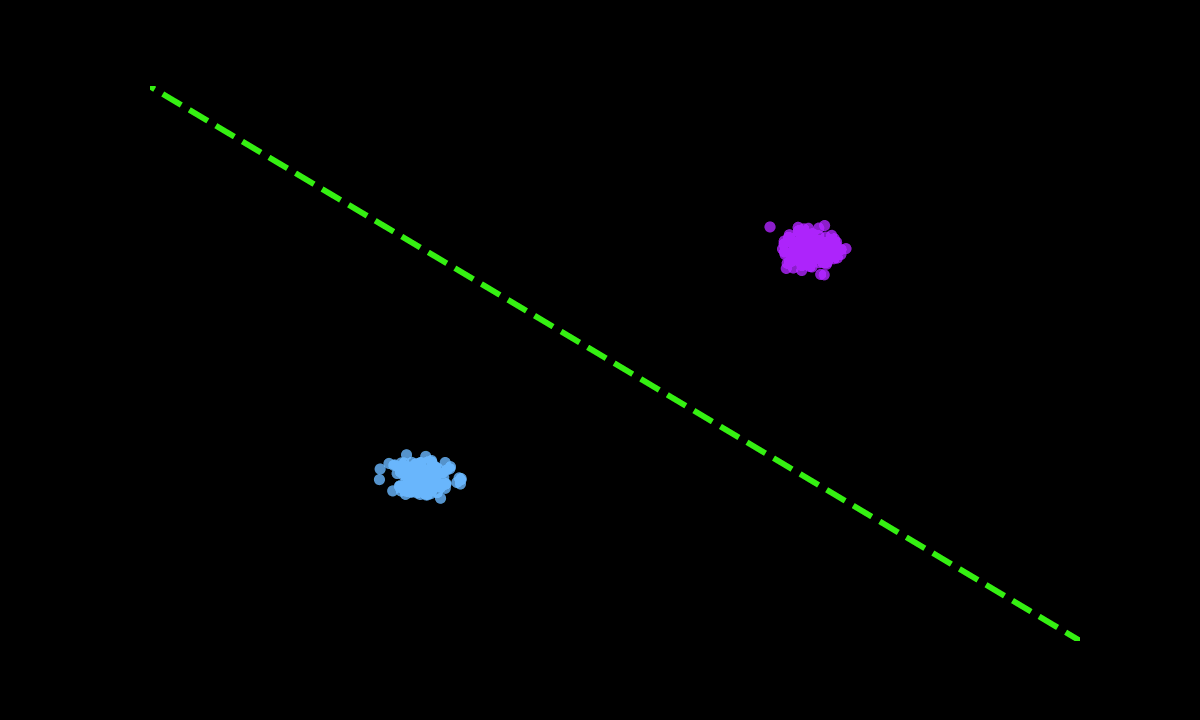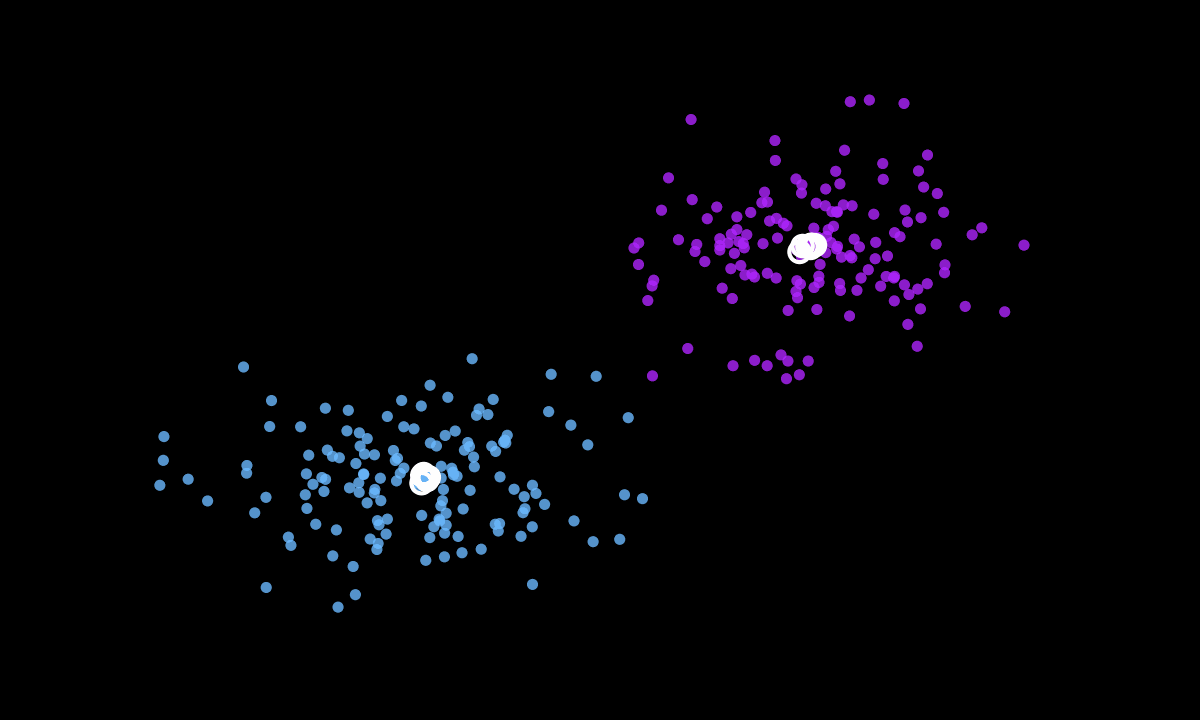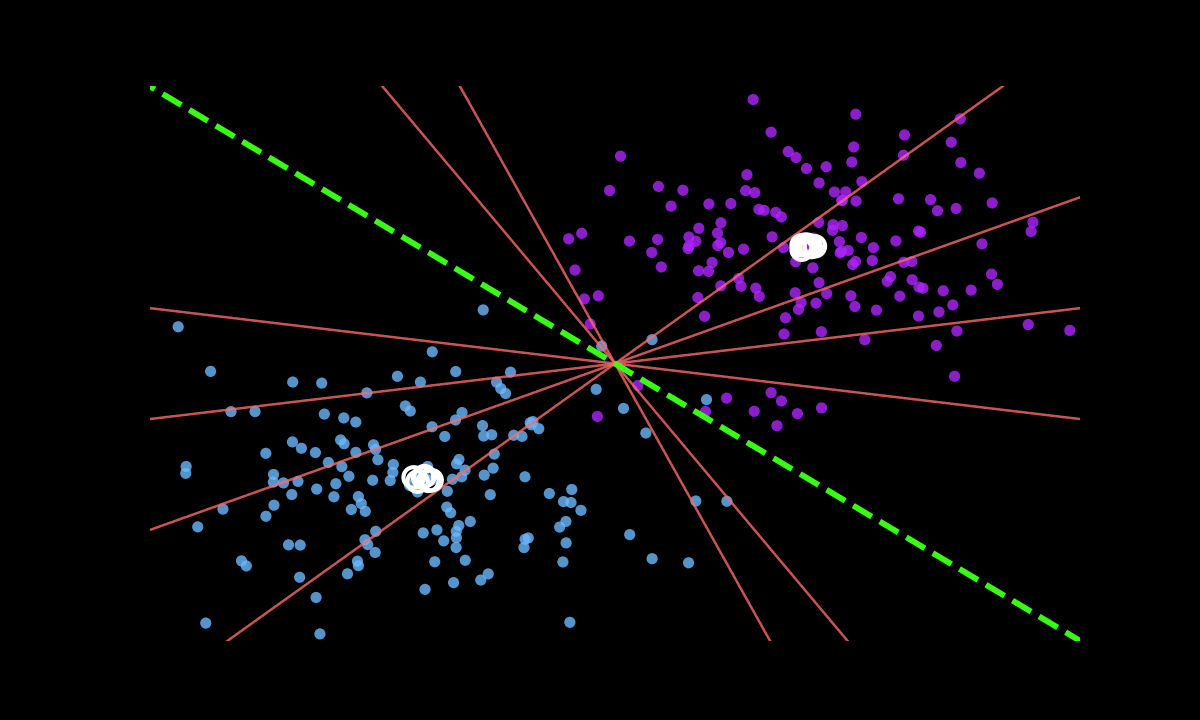
Animation: Features remain separable, but classifier boundaries misalign with small buffers
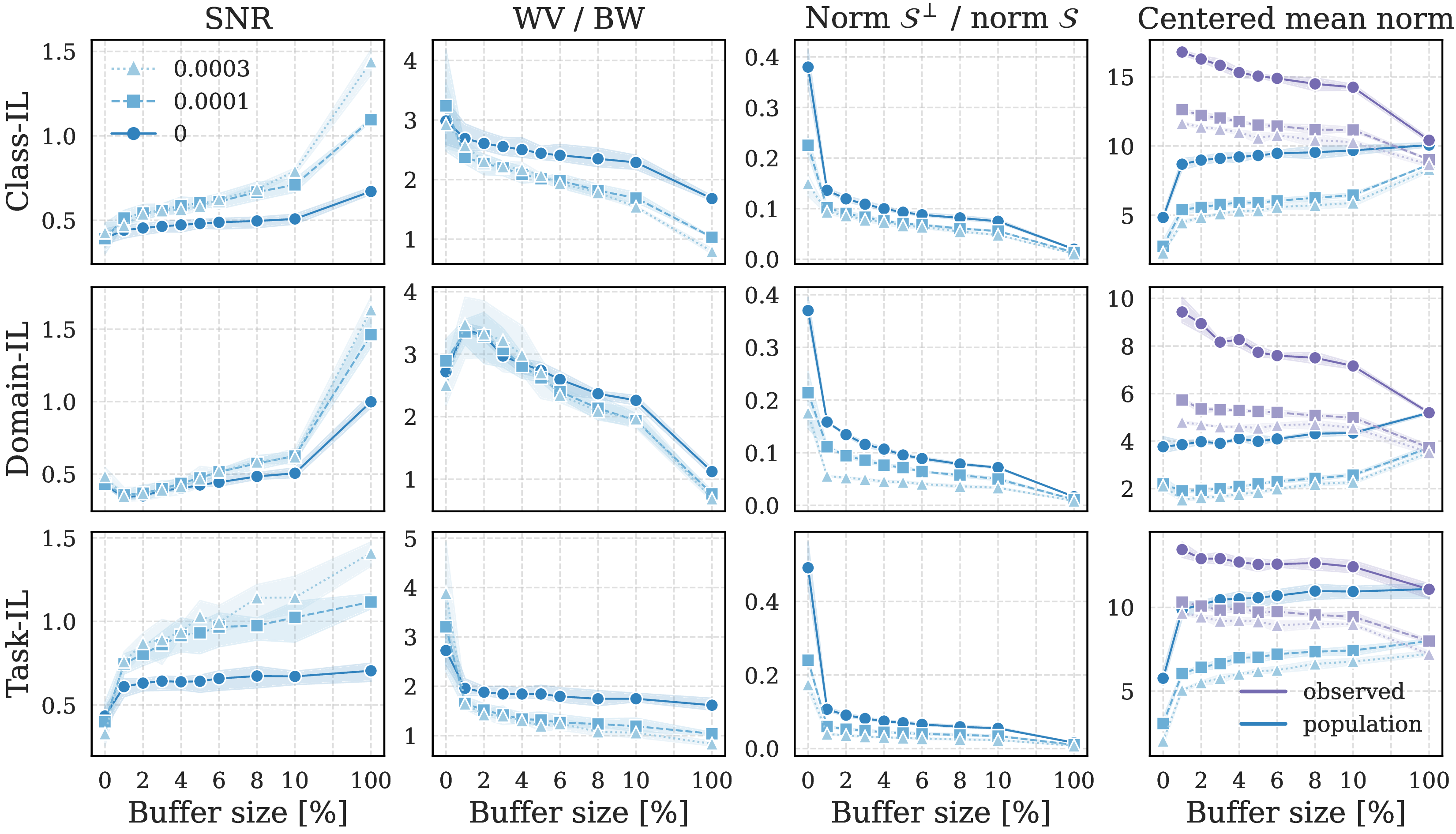
Deconstructing the Statistical Gap
Covariance Deficiency
Buffer covariance \(\hat{\Sigma}\) is rank-deficient, blind to variance in \(S^\perp\)
Rank gap persists until buffer ≈ 100%
Mean Norm Inflation
Buffer means exhibit inflated norms due to repulsive forces
\(\|\hat{\mu}_c\| > \|\mu_c\|\) for small buffers
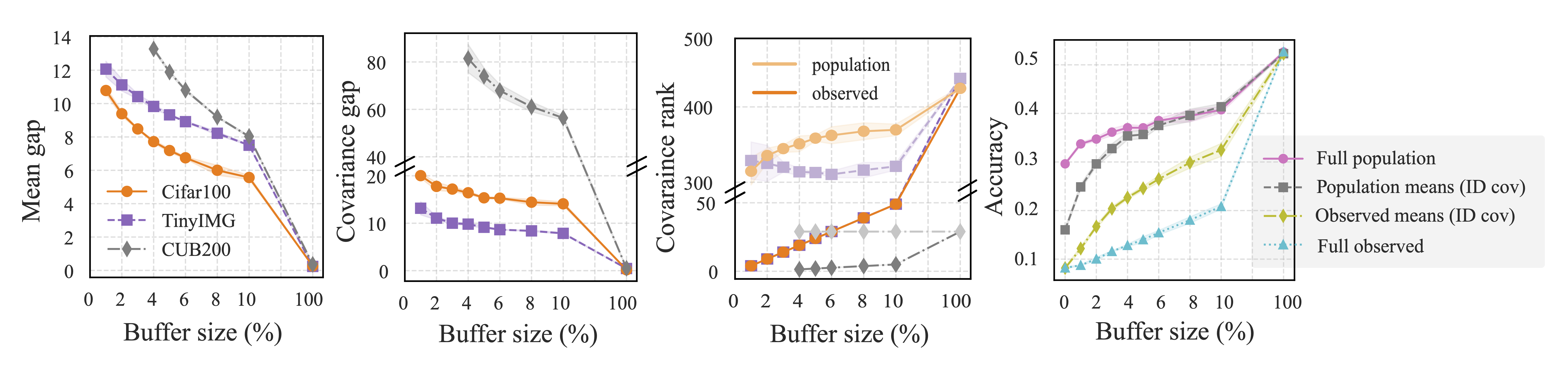
Gap between population and buffer statistics persists across buffer sizes